Invalid input. Special characters are not supported.
AI has become a buzzword, often associated with the need for powerful compute platforms to support data centers and large language models (LLMs). While GPUs have been essential for scaling AI at the data center level (training), deploying AI across power-constrained environments — like IoT devices, video security cameras and edge computing systems — requires a different approach. The industry is now shifting toward more efficient compute architectures and specialized AI models tailored for distributed, low-power applications.
We now need to rethink how millions — or even billions — of endpoints evolve beyond simply acting as devices that need to connect to the cloud for AI tasks. These devices must become truly AI-enabled edge systems capable of performing on-device inference with maximum efficiency, measured in the lowest tera operations per second per watt (TOPS/W).
Challenges to real-time AI compute
As AI foundation models grow significantly larger, the cost of infrastructure and energy consumption has risen sharply. This has shifted the spotlight onto data center capabilities needed to support the increasing demands of generative AI. However, for real-time inference at the edge, there remains a strong push to bring AI acceleration closer to where data is generated — on devices themselves.
Managing AI at the edge introduces new challenges. It’s no longer just about being compute-bound — having enough raw tera operations per second (TOPS). We also need to consider memory performance, all while staying within strict limits on energy consumption and cost for each use case. These constraints highlight a growing reality: both compute and memory are becoming equally critical components in any effective AI edge solution.
As we develop increasingly sophisticated AI models capable of handling more inputs and tasks, their size and complexity continue to grow, demanding significantly more compute power. While TPUs and GPUs have kept pace with this growth, memory bandwidth and performance have not advanced at the same rate. This creates a bottleneck: even though GPUs can process more data, the memory systems feeding them struggle to keep up. It’s a growing challenge that underscores the need to balance compute and memory advancements in AI system design.
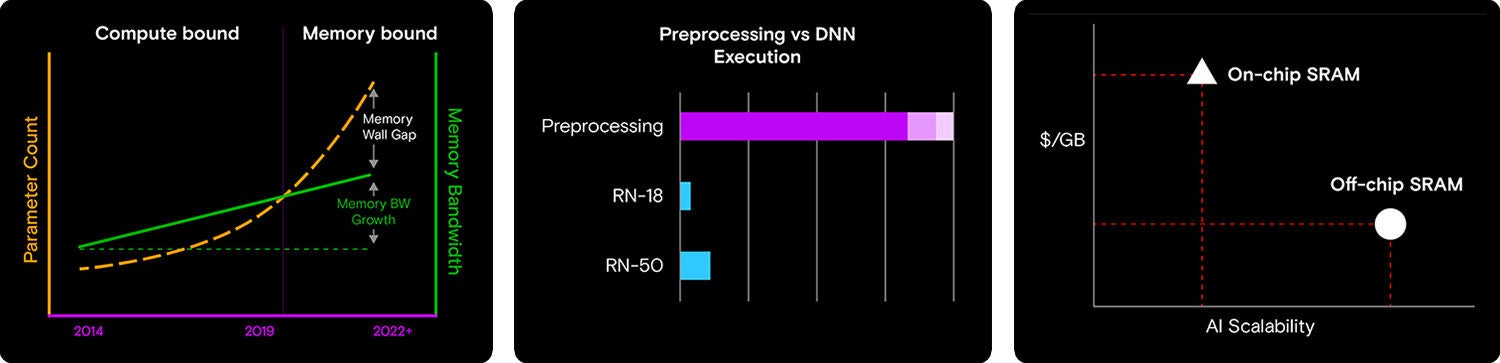
Embedded AI reveals memory as a critical consideration.

Generative AI is increasingly being integrated into industrial computing.
Memory bandwidth have created bottlenecks in embedded edge AI systems and limit performance despite advances in model complexity and compute power.
Another important consideration is that inference involves data in motion — meaning the neural network (NN) must ingest curated data that has undergone preprocessing. Similarly, once quantization and activations pass through the NN, post-processing becomes just as critical to the overall AI pipeline. It’s like building a car with a 500-horsepower engine but fueling it with low-octane gas and equipping it with spare tires. No matter how powerful the engine is, the car’s performance is limited by the weakest components in the system.
A third consideration is that even if SoCs include NPUs and accelerator features — adding some small RAM cache as part of their sandbox, the cost of these multi-domain processors are increasing the bill of materials (BOM) as well as limiting its flexibility.
The value of an optimized, dedicated ASIC accelerator cannot be overstated. These accelerators not only improve neural network efficiency but also offer flexibility in supporting a wide range of AI models. Another benefit of an ASIC accelerator is that it is tuned to offer the best TOPS/W — making it more suitable for edge applications that will benefit from lower power consumption, better thermal ranges and broader application use — from autonomous farm equipment, video surveillance cameras, as well as autonomous mobile robots in a warehouse.
Synergy of compute and memory
Co-processors that integrate with edge platforms enable real-time deep learning inference tasks with low power consumption and high cost-efficiency. They support a wide range of neural networks, vision transformer models and LLMs.
A great example of technology synergy is the combination of Hailo’s edge AI accelerator processor with Micron’s low-power DDR (LPDDR) memory. Together, they deliver a balanced solution that provides the right mix of compute and memory while staying within tight energy and cost budgets — ideal for edge AI applications.
As a leading provider of memory and storage solutions, Micron’s LPDDR technology offers high-speed, high-bandwidth data transfer without sacrificing power efficiency to eliminate the bottleneck in processing real-time data. Commonly used in smartphones, laptops, automotive systems and industrial devices, LPDDR is especially well-suited for embedded AI applications that demand high I/O bandwidth and fast pin speeds to keep up with modern AI accelerators.
For instance, LPDDR4/4X (low-power DDR4 DRAM) and LPDDR5/5X (low-power DDR5 DRAM) offer significant performance gains over earlier generations. LPDDR4 supports speeds up to 4.2 Gbits/s per pin with bus widths up to x64. Micron’s 1-beta LPDDR5X doubles that performance, reaching up to 9.6 Gbits/s per pin, and delivers 20% better power efficiency compared to LPDDR4X. These advancements are crucial for supporting the growing demands of AI at the edge, where both speed and energy efficiency are essential.
One of the leading AI silicon providers that Micron’s collaborates with is Hailo. Hailo offers breakthrough AI processors uniquely designed to enable high performance deep learning applications on edge devices. Hailo processors are geared towards the new era of generative AI on the edge, in parallel with enabling perception and video enhancement through a wide range of AI accelerators and vision processors.

For example, the Hailo-10H AI processor, delivering up to 40 TOPS, offering an AI edge processor for countless use cases. . . According to Hailo, the Hailo-10H’s unique, powerful and scalable structure-driven dataflow architecture takes advantage of the core properties of neural networks. It enables edge devices to run deep learning applications at full scale more efficiently and effectively than traditional solutions, while significantly lowering costs.
Putting the solution to work
AI-generated content may be incorrect., PictureAI vision processors are ideal for smart cameras. The Hailo-15 VPU system-on-a-chip (SoC) combines Hailo’s AI inferencing capabilities with advanced computer vision engines, generating premium image quality and advanced video analytics. The AI capacity of their vision processing unit can be used for both AI-powered image enhancement and processing of multiple complex deep learning AI applications at full scale and with excellent efficiency.

AI-generated content may be incorrect., PictureWith the combination of Micron’s low power DRAM (LPDDR4X) rigorously tested for a wide range of applications and Hailo’s AI processors, this combination allows a broad range of applications. From the extreme temperature and performance needs of industrial and automotive applications to the exacting specs of enterprise systems. Micron’s LPDDR4X is ideally suitable to Hailo’s VPU as it delivers high performance, high-bandwidth data rates without compromising power efficiency.
Winning combination
As more use cases are taking advantage of AI enabled devices, developers need to consider how millions (even billions) of endpoints have to evolve to not be just cloud agents, but truly be AI-enabled edge devices that can support on-premise inference, at the lowest TOPS/W. With processors designed from the ground-up to accelerate AI for the edge, and low-power, reliable, high performance LPDRAM, edge AI can be developed for more and more applications.
