Evolving data needs
Since computers have been around, efficiently getting information to and from the processors has been challenging. The dreaded stacks of punch cards, magnetic tape reels and then floppy drives gave way to spinning hard drives where large (for that time) amounts of data could be read and stored quickly. These drives were connected to a single computer, and if a user wanted to move data between computers, sneakernet and then FTP were the best options. But these approaches resulted in many copies of the same file that were difficult to keep in sync and manage.
In the mid-1980s, some clever engineers at Sun Microsystems solved the file-copy problem by creating the Network File System (NFS), which let multiple computers access a file that resided in a single location. At first, this location was another computer; later, that location was on a network-attached storage (NAS) device.
Data marts, data warehouses and data silos have given way to data lakes, which is a term used to describe vast amounts of data available in non-volatile, block-addressable storage accessible over a network for a variety of users and purposes, as shown in Figure 1.
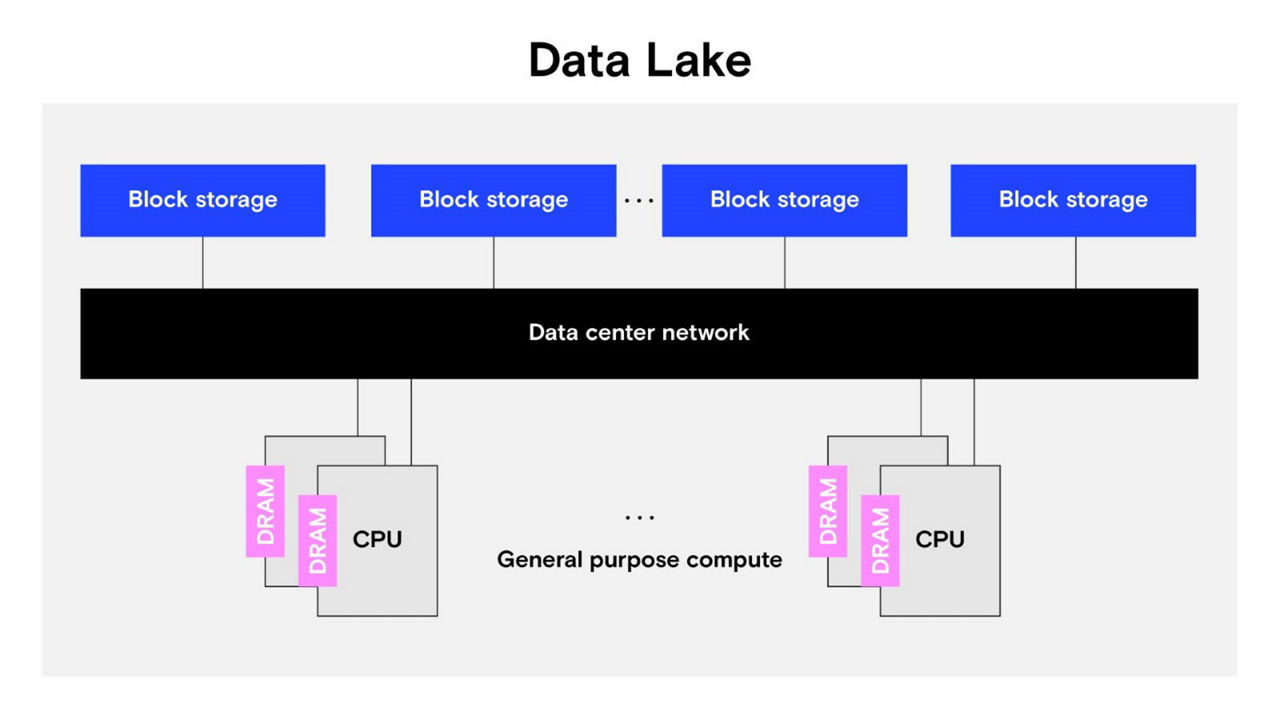
As datasets grow from megabytes to terabytes to petabytes, the cost of moving data from the block storage devices across interconnects into system memory, performing computation and then storing the large dataset back to persistent storage is rising in terms of time and power (watts). Additionally, heterogeneous computing hardware increasingly needs access to the same datasets. For example, a general-purpose CPU may be used for assembling and preprocessing a dataset and scheduling tasks, but a specialized compute engine (like a GPU) is much faster at training an AI model. A more efficient solution is needed that reduces the transfer of large datasets from storage directly to processor-accessible memory.
Several organizations have pushed the industry toward solutions to these problems by keeping the datasets in large, byte-addressable, sharable memory. In the 1990s, the scalable coherent interface (SCI) allowed multiple CPUs to access memory in a coherent way within a system. The heterogeneous system architecture (HSA)1 specification allowed memory sharing between devices of different types on the same bus. In the decade starting in 2010, the Gen-Z standard delivered a memory-semantic bus protocol with high bandwidth and low latency with coherency. These efforts culminated in the widely adopted Compute Express Link (CXLTM) standard being used today. Since the formation of the Compute Express Link (CXL) consortium, Micron has been and remains an active contributor.
CXL shared, zero-copy memory
Compute Express Link opens the door for saving time and power. The new CXL 3.1 standard allows for byte-addressable, load-store-accessible memory like DRAM to be shared between different hosts over a low-latency, high-bandwidth interface using industry-standard components.
This sharing opens new doors previously only possible through expensive, proprietary equipment. With shared memory systems, the data can be loaded into shared memory once and then processed multiple times by multiple hosts and accelerators in a pipeline, without incurring the cost of copying data to local memory, block storage protocols and latency.
Moreover, some network data transfers can be eliminated. For example, data can be ingested and stored in shared memory over time by a host connected to a sensor array. Once resident in memory, a second host optimized for this purpose can clean and preprocess the data, followed by a third host processing the data. Meanwhile, the first host has been ingesting a second dataset. The only information that needs to be passed between the hosts is a message pointing to the data to indicate it is ready for processing. The large dataset never has to move or be copied, saving bandwidth, energy and memory space.
Another example of zero-copy data sharing is a producer–consumer data model where a single host is responsible for collecting data in memory, and then multiple other hosts consume the data after it’s written. As before, the producer just needs to send a message pointing to the address of the data, signaling the other hosts that it’s ready for consumption.
Enhanced memory functionality
Zero-copy data sharing can be further enhanced by CXL memory modules having built-in processing capabilities. For example, if a CXL memory module can perform a repetitive mathematical operation or data transformation on a data object entirely in the module, system bandwidth and power can be saved. These savings are achieved by commanding the memory module to execute the operation without the data ever leaving the module using a capability called near memory compute (NMC).
Additionally, the low-latency CXL fabric can be leveraged to send messages with low overhead very quickly from one host to another, between hosts and memory modules, or between memory modules. These connections can be used to synchronize steps and share pointers between producers and consumers.
Beyond NMC and communication benefits, advanced memory telemetry can be added to CXL modules to provide a new window into real-world application traffic in the shared devices2 without burdening the host processors. With the insights gained, operating systems and management software can optimize data placement (memory tiering) and tune other system parameters to meet operating goals, from performance to energy consumption. Additional memory-intensive, value-add functions such as transactions are also ideally suited to NMC.
Memory lake
Micron is excited to combine large, scale-out CXL global shared memory and enhanced memory features into our memory lake concept. A memory lake takes advantage of the new features of the CXL 3.1 specification and adds the capabilities discussed in this blog and more, as shown in Figure 2.
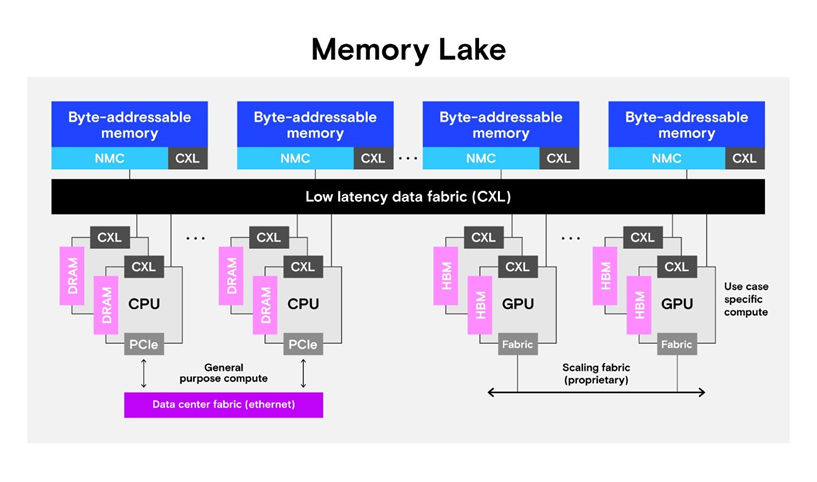
A memory lake includes the following features:
- Efficient capacity and cost
- Hundreds of terabytes to petabytes of globally addressable shared memory to allow nonsharded access to the largest datasets
- Memory tiering where the most critical data is always in the fastest memory, but costs and data persistence are controlled by keeping less critical data in more cost-effective memory
- Configurable topologies
- Performance through sharing
- Data sharing where byte-addressable data is accessible by up to dozens (or hundreds) of hosts through load-store semantics without having to be copied
- Low-latency implementation
- Sub 600 nanosecond load and store times of data
- Synchronization through the CXL fabric (less than 1 microsecond)
- Near-memory computing for accelerated performance
- Compute capabilities with the data never leaving the memory module (near- or in-memory compute)
- Native memory module support for atomic operations
1 Heterogeneous System Architecture Foundation (hsafoundation.org)
2 D. Boles, D. Waddington and D. A. Roberts, "CXL-Enabled Enhanced Memory Functions"
Scalable Memory Systems Pathfinding Group, Micron
The Advanced Memory Solutions Group engages in research, design and testing of new memory technologies. Our team of experts works closely with partners, customers, universities, and standards bodies to ensure that the Micron memory solutions remain on the leading edge of memory technology.