Login / Register
Artificial Intelligence and Machine Learning Demand High Performance Storage Series, part three: Execute
Hi again! In this edition of my Artificial Intelligence series, I wanted to look at the third, and final, major phase of an AI implementation: execution (see the overall AI process in the diagram below). As you may recall, in my previous two blogs, I reviewed the Ingest and Transformation and the Training phases of the AI process. As we saw, there can be a very dramatic impact on overall performance in those two phases created by integrating flash in the form of SSDs and memory.
In the ingest/transform phase, the faster you can get raw data from myriad sources into the AI infrastructure and transform it into a useable standardized format suitable for your modeling, the faster you will move to the train phase. While the train phase is very CPU – and more specifically GPU – centric, we showed that adding flash and memory to the solution makes a big impact. For more details, read my colleague Wes Vaske’s blog on the effect of memory and storage on AI.
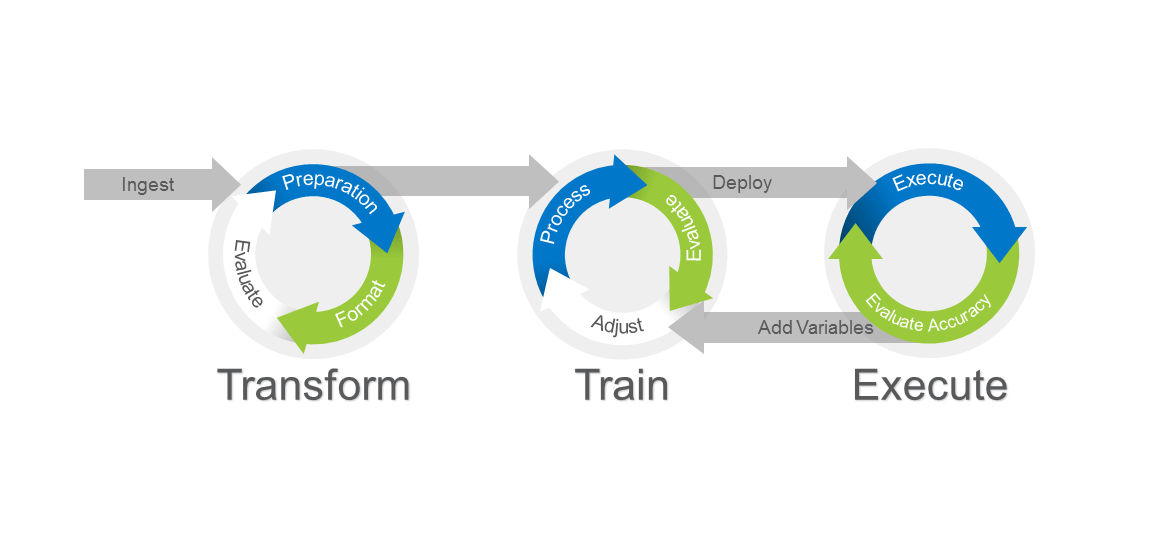
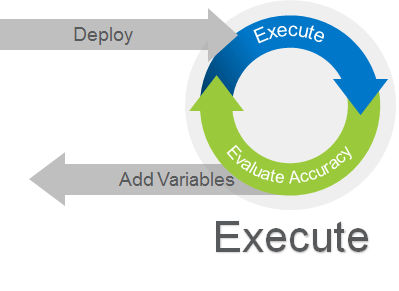
The execution phase of the AI process is where the rubber hits the road. This phase is where you realize the useful benefits of AI. In the execution phase, our trained and refined AI model must be deployed – often to various target edge devices (cameras, sensors, etc.) – and used to make decisions, also known in the AI world as “inference.” In many instances, as you are inferring, you will also need to evaluate your accuracy continually. This trend or feedback analysis is typically not done on the edge or IoT device, but as part of an analytics process that uses data captured by the devices and the inference results.
The breadth of usage scenarios is virtually unlimited and typically spans use cases that either focus predominately on real-time analysis and decision making, or scenarios requiring both real-time decision making and post-real-time analytics. Depending on the use case, there will be a different ratio of or dependence on memory and storage. Below I present a pair of illustrative real-world use cases.
Real-Time Analysis
A use case we are probably all familiar with: using our cell phone camera to identify local businesses, or using our cell phone camera as a dimensional measuring device (answering the question “how long is my couch?” for example). Depending on the phone you use, that inference is executed completely on the local device. In these examples, your phone does not need to retain the information once it has completed the inference. This scenario is purely real-time. This use case depends more on memory than storage as the smartphone processes the camera data. There is not any real need for long- or even medium-term storage in this use case. Once the inference has completed, the data - the image - is no longer needed.
Memory that provides a good balance of high-performance and low-power consumption is the focus when executing inference on these small remote/mobile devices. Micron offers low-power DRAM solutions in a variety of form-factors suitable to mobile, automotive, and custom edge devices.
Real-time Analysis with Post-Inference Analytics
In many business environments the inference process must constantly be reanalyzed to ensure that the AI inference engine is meeting expectations - a feedback loop for constant process improvement. In these use cases, flash plays a very important role. The faster you can perform this analysis, the faster you can improve your real-time inference. Also, the amount of storage required and its location will depend on several factors, whether short-term, on-device retention to long-term, off-device big data repositories. Lastly, the data retention time will also affect your decisions on the storage solution deployed.
On-device storage may be required – as it is in many automotive use cases – to meet regulatory requirements. While self-driving cars are doing massive amounts of real-time inference, they also need to retain all data from a wide variety of sensors (cameras, engine performance data, etc.) for a specific amount of time so that agencies such as the U.S. NHTSA can use it to analyze a crash. In fact, by 2020, the typical vehicle is expected to contain more than 300 million lines of code and will contain more than 1 TB (terabyte) of storage!
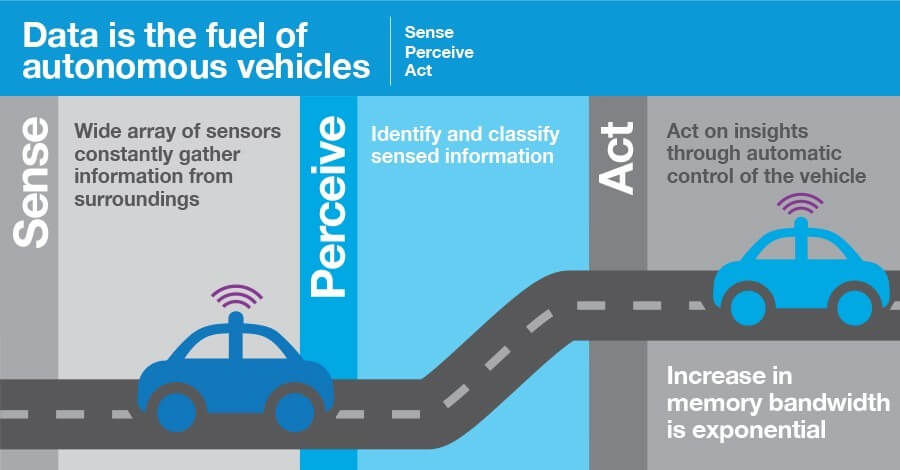
In other cases, the amount of on-device storage only needs to support the transmission of the data to a larger big-data repository for extensive post-processing analytics. This is something those of us here at Micron are keenly familiar with. As we have discussed in the past, Micron uses the data from our wafer analysis process (AI inference) to perform ongoing manufacturing process improvement. We talked about this at Data Works Summit last year where we showed that not only is storage important to the post-inference analytics, but the type of storage dramatically impacts analytics performance. In this case, even adding a single high-performance NVMe SSD to existing legacy big-data environments on HDDs can provide massive improvements.
Micron Infrastructure Accelerates Intelligence
Micron offers SSDs suitable for a wide variety of application workloads as well as industrial grade microSD cards targeted at the network edge and IoT space.
Stay tuned in to the Micron blog for more great results from our ongoing evaluation of using storage and memory for AI/ML workloads.
Learn more at micron.com/AI about these and other Micron products and how they can help you be successful in your next AI/ML project.
Stay up to date by connecting with us on Linkedin.